Spring Boot and Kafka Stream, Processing continuous data streams
Last updated on November 13, 2022 pm
Processing continuous data streams in distributed systems without any time delay poses a number of challenges. We show you how stream processing can succeed with Kafka Streams and Spring Boot.

Everything in flow: If you look at data as a continuous stream of information, you can get a lot of speed out of it.
TL;DR
Here’s the ultra-short summary:
- Stream processing is well suited to process large amounts of data asynchronously and with minimal delay.
- Modern streaming frameworks allow you to align your application architecture completely with event streams and turn your data management inside out. The event stream becomes the “ source of truth ”.
- With Kafka Streams, Kafka offers an API to process streams and map complex operations to them. meansKStreams andKTables you can also map more complex use cases that have to maintain a state. This state is managed by Kafka, so you don’t have to worry about data management yourself.
- Spring Boot offers oneStream abstraction that can be used to implement stream processing workloads.
You can find the entire project atGitHub.
Processing large amounts of data quickly – a perennial topic
In our everyday project environment, we often deal with use cases in which we have to process a continuous stream of events through several systems involved with as little delay as possible. Two examples:
- Let’s imagine a classic web shop: customers order goods around the clock. The information about the incoming order is of interest for various subsystems: Among other things, the warehouse needs information about the items to be shipped, we have to write an invoice and maybe now reorder goods ourselves.
- Another scenario: A car manufacturer analyzes their vehicles’ telemetry data to improve the durability of their vehicles. For this purpose, the components of thousands of cars send sensor data every second, which then has to be examined for anomalies.
The larger the amounts of data in both examples, the more difficult it becomes for us to scale our system adequately and to process the data in the shortest possible time. This describes a general problem: the volume of data that we are confronted with in everyday life is constantly increasing, while our customers expect us to process the data and make it usable as quickly as possible.Modern Stream Processing Frameworks should address precisely these aspects.
In this blog post, we would like to use a concrete use case to demonstrate how a stream processing architecture can be implemented with Spring Boot and Apache Kafka Streams. We want to go into the conception of the overall system as well as the everyday problems that we should take into account during implementation.
Streams and events briefly outlined
We can classify stream processing as an alternative to batch processing. Instead of “heaping” all incoming data and processing them en bloc at a later point in time, the idea behind stream processing is to view incoming data as a continuous stream: the data is processed continuously. Depending on the API and programming model, we can use a corresponding domain-specific language to define operations on the data stream. Sender and receiver do not need any knowledge about each other. The systems participating in the stream are usually decoupled from one another via a corresponding messaging backbone.
In addition to the advantages of time-critical processing of data, the concept is well suited to reducing dependencies between services in distributed systems. Through indirection via a central messaging backbone, services can now switch to an asynchronous communication model in that they no longer communicate via commands but via events. While commands are direct, synchronous calls between services that trigger an action or result in a change of state, events only transmit the information that an event has occurred. With event processing, the recipient decides when and how this information is processed. This procedure is helpful to achieve a looser coupling between the components of an overall system[1].
Using Kafka as a stream processing platform allows us to align our overall system to events, as the next section shows.
Kafka as a stream processing platform
What distinguishes Kafka from classic message brokers such as RabbitMQ or Amazon SQS is the permanent storage of event streams and the provision of an API for processing these events as streams. This enables us to turn the architecture of a distributed system inside out and make these events the “source of truth” : If the state of our entire system can be established based on the sequence of all events and these events are stored permanently, this state can be changed at any time by processing of the event log can be (re)established. Martin Kleppmann described the concept of a globally available, unchangeable event log as “turning the database inside out” .[2]. What is meant by this is that we can distribute the concepts that we traditionally provide encapsulated as a black box within a relational database (a transaction log, a query engine, indexes and caches) through Kafka and Kafka Streams to the components of a system.
To build a streaming architecture based on this theory, we use two different components from the Kafka ecosystem:
- Kafka Cluster : Provides event storage. Acts as the immutable and permanently stored transaction log.
- Kafka Streams : Provides the API for stream processing (Streams API). Abstracts the components for generating and consuming the messages and provides the programming model to process the events and map caches and queries to them[3]
In addition to aligning to events and providing APIs to process them, Kafka also comes with some mechanisms to scale with large amounts of data. The most important mechanism is partitioning: messages are distributed to different partitions so that they can be read and written in parallel as efficiently as possible. Provides a good overview of the central concepts and vocabulary in the Kafka cosmos[4].
Based on a concrete use case, we now want to show you how we can implement a distributed streaming architecture with Spring Boot and Kafka.
An exemplary use case
Let’s imagine that our customer - a space agency - commissioned us to develop a system for evaluating telemetry data from various space probes in space. The general conditions and requirements are as follows:
- We have an unspecified set of probes giving us a steady stream of telemetry readings. These probes belong to either the US Space Agency (NASA) or the European Space Agency (ESA).
- All space probes send their measurement data in the imperial system.
- Our customer is only interested in the aggregated measurement data per probe:
- What is the total distance a given probe has traveled so far?
- What is the top speed the probe has reached so far?
- Since the measurement data from the NASA and ESA probes are processed by different teams, they should be able to be consumed separately.
- Data from the ESA probes are to be converted from the imperial to the metric system.
The target architecture
In our example, we are dealing with a continuous stream of readings that we consider our events. Since we have to perform a series of transformations and aggregations on these, the use case lends itself well to processing as a stream. The need to aggregate measurement data also suggests that some part of our application needs to be able to remember a state in order to keep the summed values per probe.
To implement the use case, we divide the application into 3 subcomponents. A Kafka cluster forms the central hub for communication between the components:
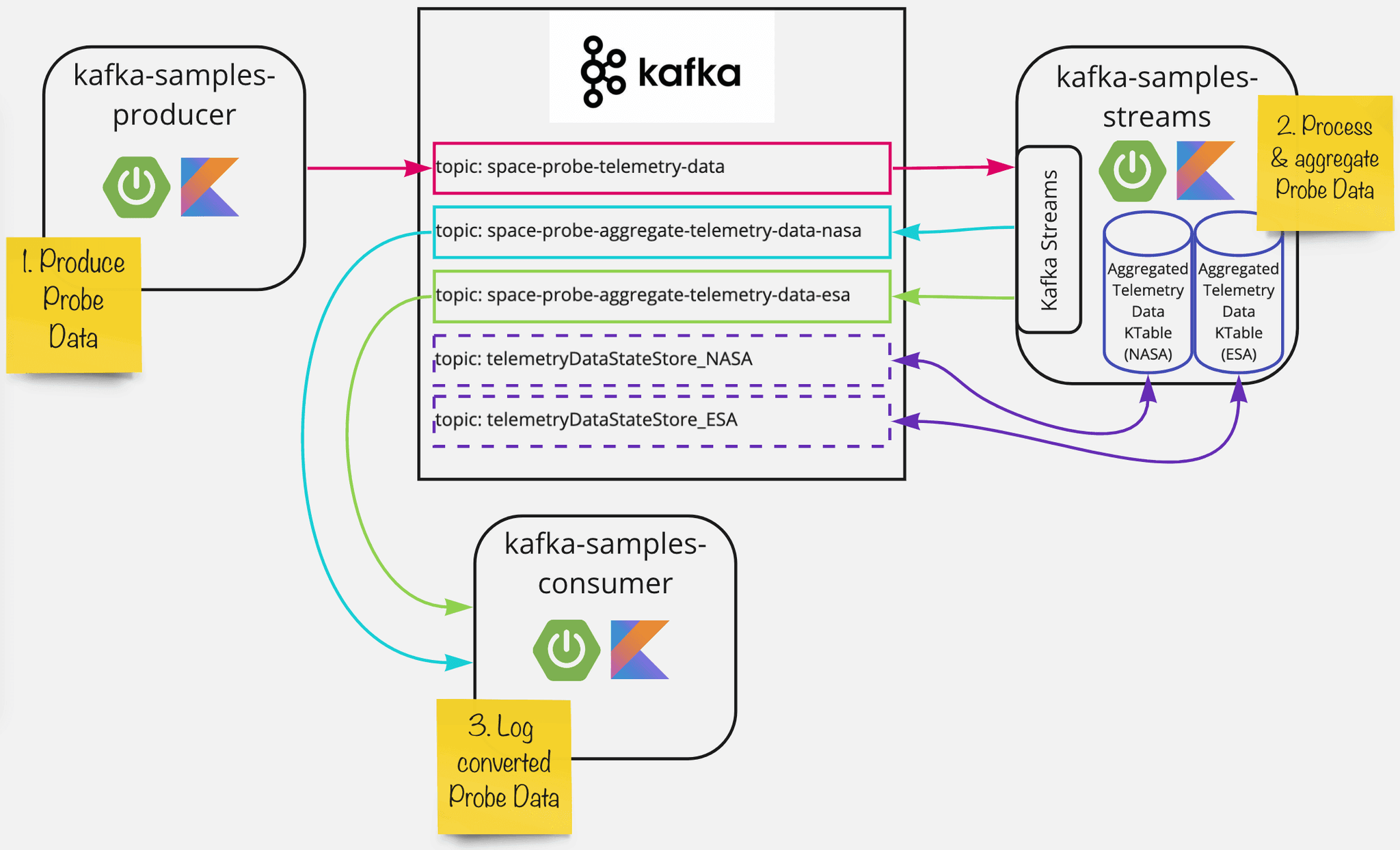
We will build this example architecture to illustrate our use case. We use Kafka as the central communication hub between our services.
We arrange the distribution of tasks between the services as follows:
- kafka-samples-producer : Converts the received measurement data into a machine-readable format and stores it on a Kafka topic. Since we don’t have any real space probes handy at the moment, we let this service generate random measurement data.
- kafka-samples-streams : Performs the calculation of the aggregated measurement data and the subdivision by measurement data for NASA or ESA. Since the previously calculated values are also included in the calculation, the application must maintain a local state. We map this using the Streams API in the form of two KTables (we already separate them by space agency here). The KTables are materialized transparently for the application by a so-called state store, which saves the history of the state in Kafka Topics.
- kafka-samples-consumer : Represents an example client service of a space agency, which is responsible for the further processing of the aggregated measurement data. In our case, this reads both output topics, in the case of the ESA, converts them to the metric system and logs these values to stdout.
Implementation of the Services
We have implemented all services with Spring Boot and Kotlin and use the for configuration and implementationSpring abstraction for streams. In the following sections we will go into the concrete implementation of the individual services.
Generation of the telemetry data (kafka-samples-producer)
To write the (fictitious) probe measurement data, we use the Kafka Producer API, available in Spring via theSpring Cloud Stream Binder for Kafka provided. We configure the service via the (application.yml) as follows:
1 | |
The configuration consists of a Kafka-specific (upper bindingsconfiguration block) and a technology-agnostic (lower bindingsconfiguration block) part, which are bound together via the binding.
In the example we create the binding telemetry-data-out-0. This declaration is based on the following convention:
1 | |
The inor outdefines whether the binding is an input (an incoming stream of data) or an output (an outgoing stream of data). With the number increasing from 0 at the end, a function can be attached to several bindings - and thus read from several topics with one function - or written to several topics.
In the Kafka-specific part, we prevent Spring from adding a Type header to every message. Otherwise, this would mean that a consumer of the message - should he not actively prevent this - does not know the class specified in the header and therefore cannot deserialize the message.
The technology-agnostic part is used in this form for all Spring Cloud Streams-supported implementations like RabbitMQ, AWS SQS, etc. destinationAll you have to do here is specify the output target ( ) – in our case, this maps to the name of the Kafka topic that we want to describe.
After the service is configured, we define a Spring component to write the metrics (TelemetryDataStreamBridge.kt):
1 | |
As an entry point into the streaming world, Spring Cloud Streaming offers two different options:
- The imperative
StreamBridge - the reactive one
EmitterProcessor
For this use case we use the StreamBridge. We can have Spring inject this and write the generated probe data to our topic. We use the ID of the respective probe as the message key, so that data from a probe always end up on the same partition. send()We pass the binding created in the configuration to the function .
Processing of the telemetry data (kafka-samples-streams)
Most of the use case is processed in this part of our application. We use the Kafka Streams API to consume the generated probe data, perform the necessary calculations, and then write the aggregated measurement data to the two target topics. In Spring Boot, we can access the Streams API via theSpring Cloud Stream Binder for Kafka Streams.
Analogous to the Producer API, we start with creating our bindings and configure our service via the file application.yml.
1 | |
To implement the feature, we use the functional style that was introduced with Spring Cloud Stream 3.0.0. To do this, we specify aggregateTelemetryData the name of our bean in the function definition that implements the function. This will contain the actual technical logic.
Since we are reading from one topic and writing to two topics, we need three bindings here:
- A
INbinding to consume our metrics - A
OUTbinding to write our aggregated measurement data for NASA - A
OUTbinding to write our aggregated measurement data for the ESA
We can view the function declared in the upper part of the configuration as a mapping of our INbindings to our OUTbindings. In order for this to be associated with the bindings, we must adhere to the Spring convention described in the previous section.
With the binding configuration complete, we can move on to implementing our business logic. To do this, we create a function that matches the name of the functional binding from our configuration. This function maps our Kafka Streams topology and calculation logic (KafkaStreamsHandler.kt):
1 | |
In order to calculate the aggregated telemetry data per probe, we have to solve three problems in the implementation of the function:
Implementation of the calculation
The Kafka Streams API provides a set of predefined operations that we can apply to the incoming stream to perform the computation according to the use case. Since we need to separate the aggregated probe data by space agency, we first use the operation, which returns branch()an array of as a result . KStreamWe get two streams, which are now already separated by space agency. The probe data can now be calculated. Since the calculation is identical for both agencies, we use map()Kotlin’s operation so that we only have to define the following steps once for both streams. To group and ultimately aggregate the probe data by their Probe ID, we again use native Stream API operations. The operationaggregate() needs three parameters:
- An Initializer that determines the initial value if there is no aggregated data yet
- An Aggregator function that determines our calculation logic for aggregating the metrics
- The serializers/deserializers to use to store the aggregated values
aggregate()As a result, the operation returns one that KTablecontains the most recently calculated total value for each probe ID. Since our customers are interested in the most up-to-date data, we convert it KTableback into one KStream- every change in the KTablegenerates an event that contains the last calculated total value.
Storage of the aggregated measurement data
The aggregate()function that we use in our example to calculate the total values is a so-called stateful operation - i.e. a stateful operation that requires a local state in order to be able to take into account all previously calculated values for calculating the currently valid total value. The Kafka Streams API handles the management of state for us by KTablematerializing the operation a . One KTablecan be thought of as a changelog for key/value pairs, which allows us to persist (and restore if necessary) a local state. KTablesare in the Kafka cluster by so-called _state stores_materialized. The state store uses a topic managed by Kafka to persist data in the cluster. This saves us from having to manage other infrastructure components, such as a database to keep track of the status.
Delivery to the various space agencies
In order to supply NASA and ESA with the aggregated measurement data relevant to them, we used the operation before the calculation branch(). As a result, our function has a return value of Array>, whose indices correlate with the space agencies. In our case, this means that Array[0]the data is from NASA and Array[1]the data from ESA. This division in turn matches our binding config.
The resulting KStreams are our aggregation result and are written to the two output topics.
Consume the telemetry data (kafka-samples-consumer)
To read the aggregated probe measurement data, we use the Kafka Consumer API, which, like the Producer, is available via theSpring Cloud Stream Binder for Kafka provided. We configure the service for this as follows (application.yml):
1 | |
We continue according to the familiar pattern: We implement beans that implement the binding, starting with NASA.
We create a function that Consumerimplements (seeKafkaConsumerConfiguration.kt). This means that we have an input but no output to another topic and the stream ends in this function.
The consumer for ESA follows the same pattern as the consumer for NASA, the only difference being that the data transmitted is converted from the imperial system to the metric system. We have this functionality in the initfunction of our classMetricTelemetryData.kt capsuled.
With the implementation of the consumer, our stream processing pipeline is complete and all requirements have been implemented.
The finished solution in action
If we start our services now, after a few seconds we should see the first aggregated probe data in the Consumer Service log. Additionally, we can take a look atAKHQ Get an overview of the topics and messages in Kafka:
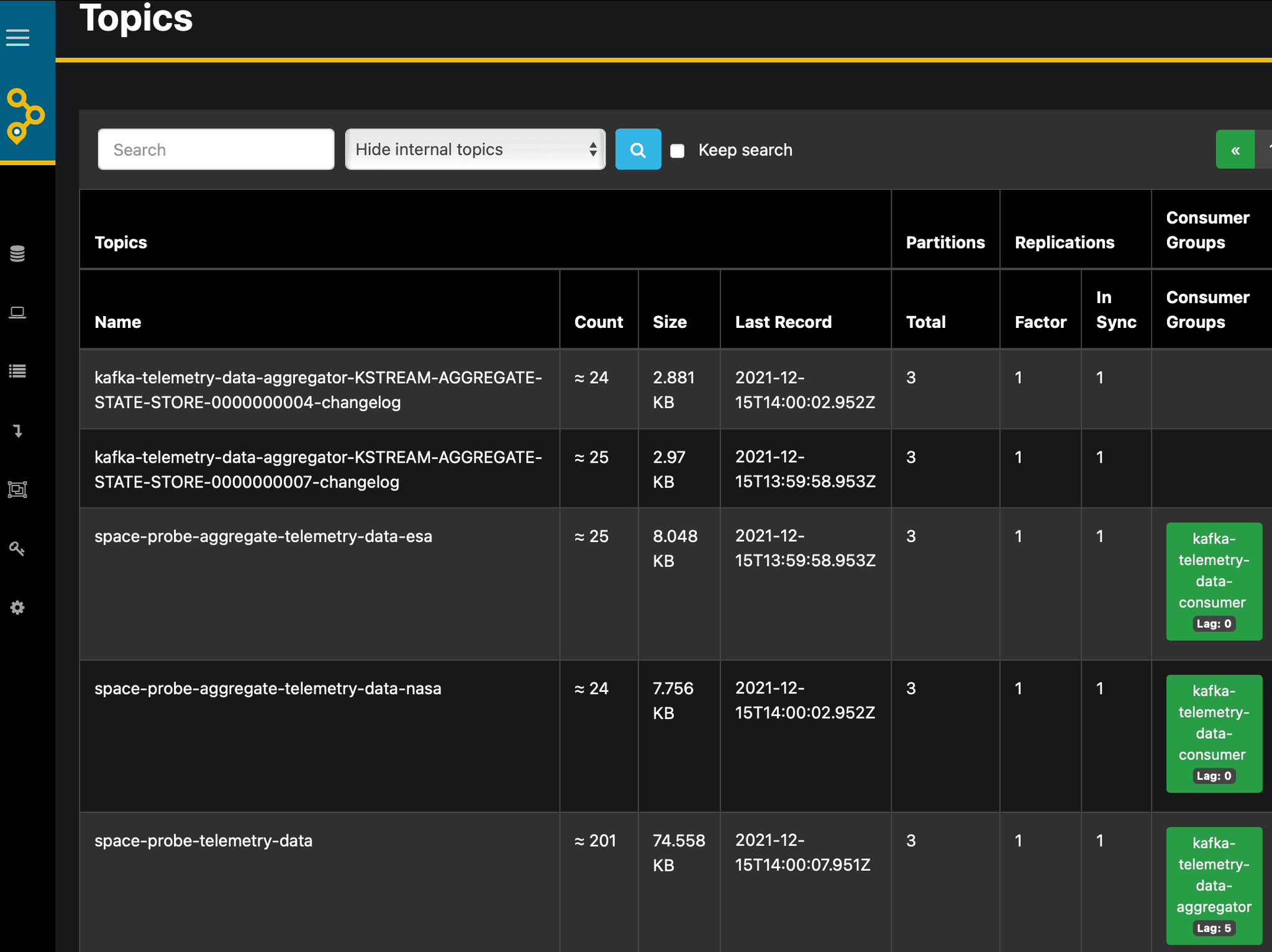
We recognize the inbound and outbound topics accessed by our services, as well as the state stores that our aggregator service has materialized behind the scenes for us in the form of Kafka topics.
Lessons learned
If you are now thinking about using the whole thing in your projects, we have prepared some questions and argumentation aids for you so that you can make the right decision for you.
When should you think about using stream processing?
Stream processing can be useful wherever you are faced with processing large amounts of data and time delays need to be minimized. The decision for or against stream processing should not be based on a single component - the solution should fit the overall architecture of the system and the problem. If your use case has the following attributes, stream processing could be a solution:
- You are faced with a constant stream of data. Example: IoT devices continuously send you sensor data.
- Your workload is continuous and does not have the character of a data delivery. Example: You receive a data export from an old system once a day and must be able to definitely determine the end of a delivery, for example. Batch processing usually makes more sense here.
- The data to be processed are time-critical and must be processed immediately. In the case of larger amounts of data or complex calculations, you always have to think about the scalability of your services in order to keep the processing time low. Streams are suitable for this because you can scale horizontally quite easily through partitioning and asynchronous event processing.
Should you use Kafka for your stream processing workloads?
We give a cautious “yes” to that . Kafka’s data storage, paired with the Stream Processing API, is a powerful tool and is offered by various providers as a service . This flattens the learning curve and minimizes maintenance. In event-driven use cases, this feels good and right. Unfortunately, we have seen several times that Kafka is used in application architectures as a pure message bus, for batch workloads or in situations where synchronous communication between services would have made more sense. The advantages of Kafka and event-driven architectures remain unused or worse: we find it more difficult than necessary to solve the problem.
If Kafka is already present in your architecture and your problem fits the technology, we would recommend you to start with theStream API capabilities to deal with - data pipelines can often be set up without additional infrastructure components and you can do without components such as relational databases or in-memory data stores. Confluent offers very goodDocuments to get you started an.
In cases where you cannot use Kafka as a service , the effort involved in setting up a Kafka cluster and operating it yourself can outweigh the benefits. In these cases, it may therefore make more sense to use a classic message broker and a relational database.
Should you implement stream processing workloads with Kafka Streams and Spring Boot?
Clear answer: It depends. If you are already using Spring Boot across the board in your projects, theSpring Streams abstraction save some time when commissioning new services, since configuration and implementation always follow a very similar scheme and we can hide some of the complexity during implementation. However, the Spring path is not quite perfect. Here are the issues that caused us pain:
- Conventions & Documentation : The configuration with the Spring abstraction consists of a few conventions that are not always properly documented and are sometimes non-transparent, which can cost nerves and time. At the time of writing this article, parts of the Spring documentation were out of date (e.g. the functional programming paradigm we are using is not yet mentioned in the current version of the documentation)
- Error Handling : When using the Stream Binder for Kafka Streams as in our classKafkaStreamsHandler.kt There is currently no convenient solution for handling exceptions that occur outside of deserialization using on-board tools (we define what should happen to errors during deserialization inapplication.yml). The only solution for this at the moment isto implement error handling past the Streams API or ensure that any deserialization errors are caught. Provides an exemplary approachTelemetryAggregationTransformer.kt. By bypassing the Streams API, we can handle errors at the message level, for example by
try/catchimplementing logic. Since we have descended an abstraction level in this example, we unfortunately also lose the automatic state managementKTables- we have to manage state stores ourselves if necessary. In this case, unfortunately, you currently have to weigh up what is more important to you. - Up-to- dateness : The Spring Dependencies are always a few Kafka releases behind, so that not all features can always be used immediately (see previous point).
As an alternative to the Spring abstraction, there are various freely usable libraries to integrate the concepts from Kafka Streams into various tech stacks. Confluent offerswell-documented step-by-step recipes for a wide range of supported environments and programming languages to keep the barriers to entry low, regardless of your environment. In this respect, you are free to decide here. If you feel comfortable with Spring Boot: great! If not: that’s ok too!
A few final words
In this blog post, we have demonstrated how you can implement the concepts of stream processing using a concrete use case with Spring Boot and Kafka Streams. We hope that with Stream Processing you now have another tool in your toolbox and that you can now approach your next project with complete peace of mind.
You can find the complete code for our sample project atGitHub.
bonus material
In order not to go beyond the scope of our blog post, we have limited ourselves to a fairly simple use case. However KTables, much more demanding scenarios can also be implemented with . Another slightly more complex example (how do we merge multiple incoming streams?) can be found in our GitHub repo on aseparate branch. We combine the incoming streams in the classKafkaStreamsHandler.kt using the join()operation.
credentials
[1] Ben Stopford (2018):Designing Event Driven Systems , S. 29 ff.
[2] Martin Kleppmann (2015): Turning the Database inside-out with Apache Samza
[3] Apache Software Foundation (2017): Kafka Streams Core Concepts
[4] Apache Software Foundation (2017): Kafka Main Concepts and Terminology